원문출처: https://ieeexplore.ieee.org/document/9694633
Follow My Eye: Using Gaze to Supervise Computer-Aided Diagnosis
When deep neural network (DNN) was first introduced to the medical image analysis community, researchers were impressed by its performance. However, it is evident now that a large number of manually labeled data is often a must to train a properly function
ieeexplore.ieee.org
✨ ABSTRACT
흔히들 CAD라고 하는 Computer-Aided Diagnosis를 구현하기 위해서는
전문의에 의해 라벨링 된 데이터가 아주 많이 필요하다. 이는 time-consuming하고 expensive하다.
이 paper는 이러한 expensive data 문제를 해결 하기 위해
단순 라벨링 뿐 아니라 전문의 Eye tracking에서 얻어낸 gaze supervision을 이용한 Attention map도 함께 input으로 사용하면 성능 향상을 보일 수 있을 것이라는 가설에서 출발했고, 이를 입증했다.
✨ BACKGROUND
이러한 new supervision idea를 모델링 하는 과정에서 참고된 여러 Related works가 있다.
📍
우선 딥러닝에서 Attention Mechanism에 관한 연구들이다.
Attention 기반 CNN은 크게 channel attention과 spatial attention으로 나뉘는데, channel attention은 서로 다른 conv. layer는 output에 서로 다른 영향을 미친다는 가정을 기반으로 하고, spatial attention은 서로 다른 location이 output에 서로 다른 영향을 미친다는 가정을 기반으로 한다. Attention 기반 CNN은 일반적으로 역전파에서 gradient-based activation을 조사하는 과정으로 이루어진다. 대표적으로 CAM을 쓰는 방법, Grad-CAM을 쓰는 방법이 있다. (CAM: Class Activation Map에 관해서는 추후 별도 포스트로 다루도록 하겠다. -> 여기 url.)
1. K. Li, Z. Wu, K.-C. Peng, J. Ernst, and Y. Fu, “Tell me where to look: Guided attention inference network,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 9215–9223.
: 이 paper에 따르면 CAM을 기반으로 segmentation mask를 이용해 network에게 attention map을 부여해 attention을 강요하는 방식으로 weakly-supervised image segmentation task의 성능을 올릴 수 있다. (-> 이 논문도 리뷰해야겠다! 여기 url.)
2. X. Ouyang et al., “Learning hierarchical attention for weakly-supervised chest X-ray abnormality localization and diagnosis,” IEEE Trans. Med. Imag., vol. 40, no. 10, pp. 2698–2710, Oct. 2021.
: 이 연구에서는 흉부 X-ray 이미지의 abnormal location을 찾아내는 task에서 bounding box를 활용한 network attention mechanism을 이용해 accuracy를 향상시켰다.
📍
그리고 본 paper에서는 'studies leveraging human visual attention in learning-based medical image analysis'가 거의 없다면서, eye tracking을 attention-based CNN에 연관지은 자신들의 논문의 중요성을 다시 한번 언급하고 있다.
하지만 human visual attention 대신 mouse clicks를 attention-based CNN과 연관지어 연구한 paper가 있다.
1. L. Li, M. Xu, X. Wang, L. Jiang, and H. Liu, “Attention based glaucoma detection: A large-scale database and CNN model,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 10571–10580.
: 이 연구에서는 human attention을 mouse click을 통해 얻어내 attention-based CNN을 활용하여 녹내장 검출 task의 성능을 높였다.
-> 하지만 본 paper에서는 이 연구에 대해 mouse click은 eye tracking과는 달리 참가자(전문의)에게 추가적인 노력을 과하게 요구하는 방식이라고 지적하고 있다.
📍
다음으로 아래 연구들은 전부 eye tracking과 diagnosis 자체가 어떤 관계가 있는지에 대한 연구다.
1. D. P. Carmody, C. F. Nodine, and H. L. Kundel, “Finding lung nodules with and without comparative visual scanning,” Perception Psychophys., vol. 29, no. 6, pp. 594–598, Nov. 1981.
: 이 연구는 "방사선 전문의의 scanning strategy가 진단의 false negative error에 영향을 줌." 을 밝혔다.
2. M. A. Lago, I. Sechopoulos, F. O. Bochud, and M. P. Eckstein, “Measurement of the useful field of view for single slices of different imaging modalities and targets,” J. Med. Imag., vol. 7, no. 2, 2020, Art. no. 022411.
: 이 연구는 "이미지 modality(양식)과 target(진단 목표)에 따라 방사선 전문의의 FOV가 매우 달라짐." 을 밝혔다.
3. H. L. Kundel, C. F. Nodine, E. A. Krupinski, and C. Mello-Thoms, “Using gaze-tracking data and mixture distribution analysis to support a holistic model for the detection of cancers on mammograms,” Academic Radiol., vol. 15, no. 7, pp. 881–886, Jul. 2008.
: 이 연구는 "방사선 이미지 진단에서 the first second of viewing의 57%에 lesions가 포함됨." 을 밝혔다.
4. S. Voisin, F. Pinto, S. Xu, G. Morin-Ducote, K. Hudson, and G. D. Tourassi, “Investigating the association of eye gaze pattern and diagnostic error in mammography,” Proc. SPIE, vol. 8673, Mar. 2013, Art. no. 867302.
: 이 연구는 "방사선 이미지 진단에서 gaze fixations와 diagnostic error 간에 highly correlated 관계가 있음." 을 밝혔다.
5. R. Bertram et al., “Eye movements of radiologists reflect expertise in CT study interpretation: A potential tool to measure resident development,” Radiology, vol. 281, no. 3, pp. 805–815, Dec. 2016.
: 이 연구는 "CT 이미지 진단에서 lesions가 있을 때 전문의는 비교적 longer fixations와 shorter saccades를 보임." 을 밝혔다.
6. S. Mallett et al., “Tracking eye gaze during interpretation of endoluminal three-dimensional CT colonography: Visual perception of experienced and inexperienced readers,” Radiology, vol. 273, no. 3, pp. 783–792, Dec. 2014.
: CT 이미지 Eye tracking data를 이용해 experienced radiologist와 inexperienced radiologist 간의 identification 능력을 구분한 연구다. 그 결과 "experienced radiologist가 higher rates of polyp identification을 보임."을 밝혔다.
📍
마지막으로, Eye-tracking을 CAD을 접목한 기존 다른 연구들이 있다.
1. J. N. Stember et al., “Eye tracking for deep learning segmentation using convolutional neural networks,” J. Digit. Imag., vol. 32, no. 4, pp. 597–604, Aug. 2019.
: Eye-tracking data를 supervision으로 CNN을 이용해 segmentation task에 test하고 그 결과가 Hand Annotation을 통해 생성된 결과와 거의 유사하다는 것을 입증했다. (-> 이 논문도 리뷰해야겠다! 여기 url.)
2. S. Mall, E. Krupinski, and C. Mello-Thoms, “Missed cancer and visual search of mammograms: What feature-based machine-learning can tell us that deep-convolution learning cannot,” Proc. SPIE, vol. 10952, Mar. 2019, Art. no. 1095216.
: 유선 촬영 이미지에서 숨겨진 유방암을 찾기 위한 task에서 human visual attention과 CNN 사이 관계를 조사한 연구다. CNN을 이용해 전문의들의 visual search behavior를 모델링했다.
3. A. Karargyris et al., “Creation and validation of a chest X-ray dataset with eye-tracking and report dictation for AI development,” Sci. Data, vol. 8, no. 1, pp. 1–18, Dec. 2021. 그리고 A. Goldberger et al., “PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals,” Circulation, vol. 101, no. 23, pp. e215–e220, 2000.
: 이 두 논문이 본 논문과 가장 비슷한 연구를 진행했다고 하는데, 이 논문들은 흉부 X-ray 이미지 dataset을 보고 eye tracking한 gaze data로부터 eye-tracking information을 얻어냈는데, 이때 gaze data를 활용하는 방식에 따라 얻어낸 information을 "temporal heatmaps"와 "static heatmaps"로 나누어 구분했다. (-> 이 논문도 리뷰해야겠다! 여기 url.)
✨ METHOD
A. Gaze Collection and Post-Processing
* Tobii 4C remote eye-tracker를 사용했다.
fixation과 saccade를 어떻게 구분할 것인지, attention level을 어떻게 정의할 것인지가 중요한데, 이 논문에서는 human eye scan path가 random walk class와 비슷한 양상을 띈다는 사실을 토대로 gaze step을 모델링했다. (D. Brockmannand T. Geisel, “Are human scanpaths levy flights?” in Proc. 9th Int. Conf. Artif. Neural Netw. (ICANN), 1999, pp. 263–268.)

여기서 gamma는 분포의 spread 정도를 나타낸다. saccade와 fixation을 구분하기 위해 threshold가 필요한데, 병변이 없는 healthy data를 관측할 때에는 saccade만 발생하는 것으로 간주하고 해당 데이터를 tracking한 data의 gaze step을 전부 saccade로 보고 이를 threshold로 잡았다. 따라서 threshold보다 더 긴 시간 응시한 경우는 fixation으로, 아니면 saccade로 구분짓기로 한 것이다. 그리고 나서 saccade points의 분포와 fixation points의 분포를 나누어 각각의 gamma를 gamma_s, gamma_f라 했다.
(* fixation 분포가 saccade 분포보다 더 compact하다(항상 gamma_f<gamma_s).)
이를 토대로 collected gaze를 3차원 tuple로 저장했다. (2차원의 location에 time stamp.)
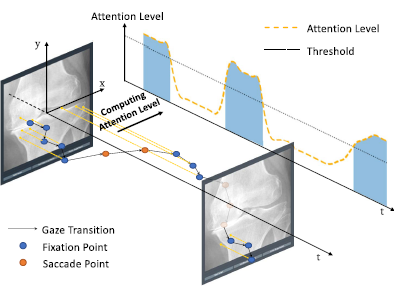
이렇게 한 이미지 안에서, 얻어진 각각의 gaze points들을 Gaussian mixtures(반지름 99pixel의 kernel)을 이용해
하나의 gaze attention map으로 합했다. (image size는 800x800 pixels)
결국 fixation, saccade를 구분하는 후처리를 거친 gaze points 버전과, 후처리를 거치지 않은 gaze points 버전이 있으며, paper에서는 이 두 버전 각각의 attention map도 만들었다. 그림으로 비교된 결과는 다음과 같다.

B. GA-Net: Gaze-Guide Attention Network
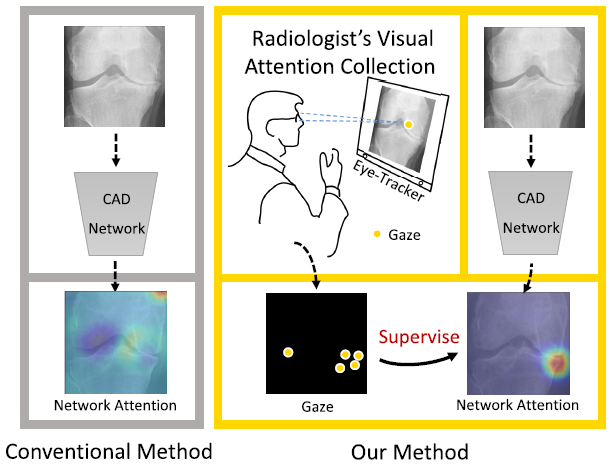
위와 같이 gaze data와 CAD Network를 모두 반영한 prediction을 만들기 위해 아래처럼 GA-Net을 구성했다.
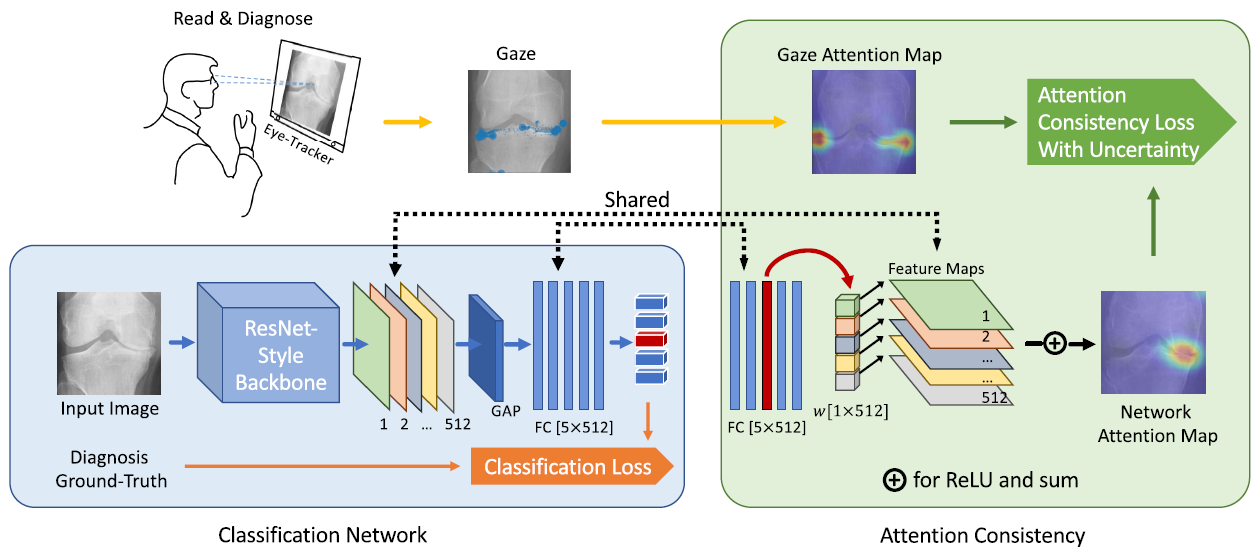
우선 CAD Network의 Classification Network part에는 ResNet을 이용했다. (What is ResNet? -> 여기 url.)
이 ResNet에는 pre-trained weights on ImageNet를 사용하고, 이후 feature maps를 거친 뒤 fully-connected 전에는 global average pooling(GAP)을 사용했다. 모델은 다음과 같이 표현되며, 여기서 S는 prediction output을 의미하고, w는 class c의 fully-connected layer의 weight, f_k는 activation of kth feature map in the last conv. layer, X와 Y는 feature maps의 size를 의미한다.
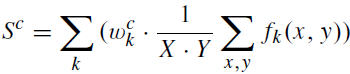
그리고 Attention Consistency에는 CAM을 사용했다. (What is CAM? -> 여기 url. B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba, “Learning deep features for discriminative localization,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016)
CAM은 간단히 말하면 feature maps부터 last conv. layer까지 fully-connected layer의 weights를 propagating하여 important region를 찾는 모델이고, 다음과 같이 간단히 표현할 수 있다.
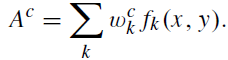
여기서 A는 attention map을 뜻한다. w_c는 Classification Network로부터 공유받은 weights다. 따라서 이 CAM은 위의 Classification Network와 fully-connected layer(의 weight)와 feature maps를 공유하여 Network attention map을 만든다.
Classification Network에서는 prediction을 Ground-Truth와 비교해 Cross entropy로 Classification Loss를 계산하고, Attention Consistency에서는 위 모델을 통해 얻어진 Attention map을 전문의 Gaze attention map과 비교해 Attention Consistency Loss를 계산한다. 그 식은 아래와 같다.
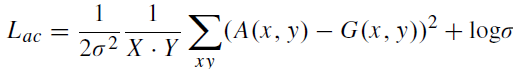
여기서 단순히 A(network attention map)와 G(gaze attention map)의 MSE를 구한 것이 아니라 거기에 보정을 했는데,
이는 G에 대한 A의 likelihood가 A를 center로 하는 gaussian 분포라고 가정한 데에서 유도 되었다.
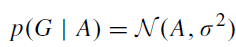
✨ RESULT
* Setup: OAI로부터 얻어진 1000장의 training images, 200장의 validation images, 1000장의 test images. Batch size: 32, initial learning rate: 0.001, epochs: 30. 관절염 상태는 0단계부터 4단계까지 존재. Gaze data는 2명의 전문의로부터 얻어짐. ACC와 MAE로 performance를 평가했는데, MAE(mean absolute error)는 prediction과 truth의 grade 차이로 계산됨. MAE 비교해는 t-test가 사용됨. 더 자세한 Setup은 원문 참고.
1. Demonstrating that by adding visual attention, the classification performance can benefit several different classification backbones.
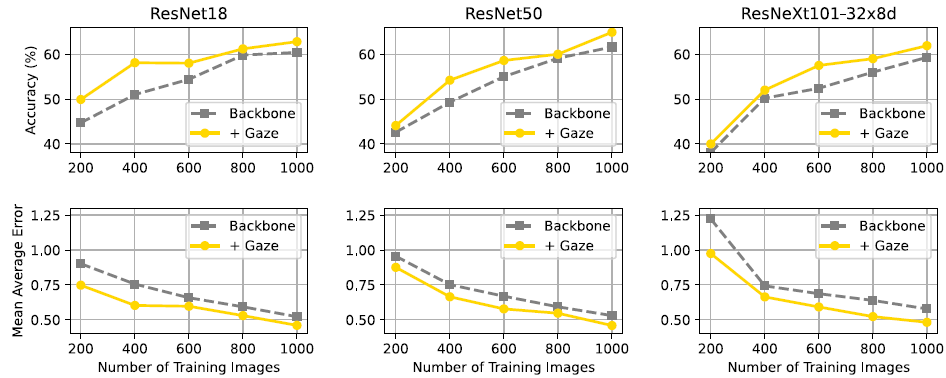

모든 경우에서 +Gaze의 Accuracy가 더 높고, Mean Average Error가 더 낮다.
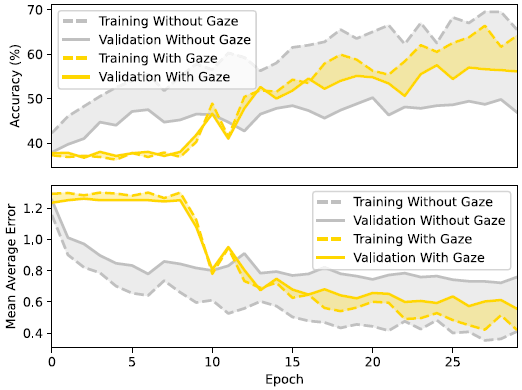
10 epochs가 지난 이후 +Gaze의 Validation Accuracy가 w/o Gaze보다 높아진다. 또한 전 epoch에서 +Gaze일 때가 Validation과 Training performance의 간극이 좁다. 이는 +Gaze일 때 overfitting 가능성도 유의미하게 낮출 수 있음을 뜻한다. 이를 통해, +Gaze network를 사용하면 small data set으로 훈련할 때에도 overfitting되지 않으면서 성능을 높일 수 있다는 초기 가설을 확인했다.
2. Comparing GA-Net with state-of-the-art methods to calidate the effectiveness of utilizing additional expert visual attention for supervision.
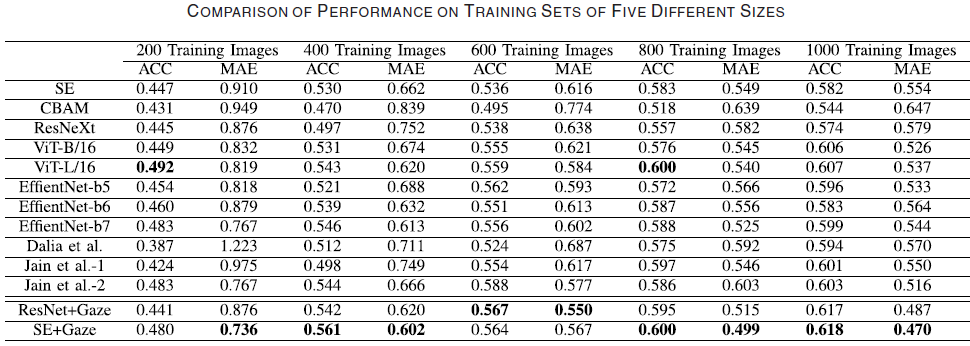
최신 모델들의 결과와 SE+Gaze, ResNet+Gaze의 결과를 비교했다. 거의 모든 경우에서 +Gaze를 한 모델의 performance가 나머지들보다 좋았다.
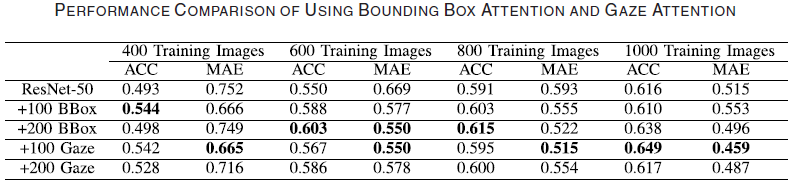
3. Comparing the visual attention generated from gaze with the attention generated by manually-drawn bounding box to verify whether eye-tracking is more efficient than the bounding box annotation for external supervision.
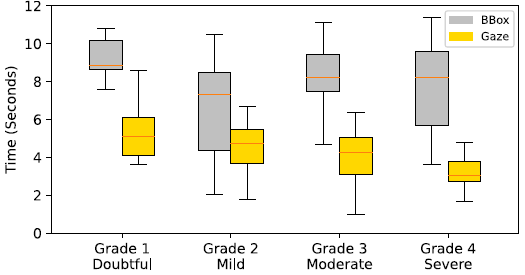
gaze data 수집에 참여한 두 명의 전문의에게서 bounding box annotations를 수집하여 Time cost와 ACC, MAE를 비교했다. Time cost는 KL-Grade마다 50장의 images를 진단할 때 평균 한 장의 이미지를 진단하는 데 걸리는 시간을 나타낸 것이다. Bounding box annotation을 라벨링하는 작업에서는 진단과 함께 그들이 abnormality의 위치를 표시하게 했다. 결과적으로 모든 KL-Grade에 걸쳐 gaze data를 수집하는 것이 bounding boxes 데이터를 수집하는 것보다 30%의 시간 감축을 보였다.
Performance 측면에서는 전반적으로 비슷한 결과가 나왔다. BBox를 쓰거나 Gaze를 쓸 때 모두 아무것도 쓰지 않았을 때보다 항상 성능이 좋았으며, 두 방식 사이에서는 성능에 큰 차이가 보이지 않는 정도였다.
결과적으로 BBox와 Gaze를 사용하는 것은 아무것도 사용하지 않을 때보다 각각 모두 좋은 성능을 보이며, Time cost 측면에서는 Gaze를 사용하는 것이 BBox를 사용하는 것보다 약 30% 유리하다.
✨ CONCLUSION AND LIMITATION
* 전문의의 gaze data를 collection 및 processing하는 toolkit를 구축했다.
* Diagnosis deep network에 attention map을 direct guidance하는 framework를 만들고 그 효과를 성공적으로 검증했다.
* knee X-ray images에 국한되었다.
* 2명의 전문의로부터 plain uncertainty model을 가정했다. 즉, 전문의들 간의 inter-variation이 고려되지 않았다.
* gaze attention과 network attention 사이 consistency를 측정하는 방식이 비교적 간단해 이 부분을 더 강화할 여지가 있다.
✨ COMMENTS
* Calibration(fixation cross) image를 사용하지 않았다. (gaze point eye tracker를 사용한 연구들은 gaze offset을 맞추기 위해 사진들 사이에 calibration image를 넣는다.) 이를 사용하면 조금 달라졌을 수도 있을 것 같다.



