https://yoomimi.tistory.com/entry/Attention-Seq2Seq-Transformer
[Deep Learning] Attention, Seq2Seq, Transformer
Vision Transformer를 이해하기 위해 필수적인 개념들을 한데 정리해보려고 한다.우선 RNN, LSTM, GRU에 관한 포스팅은 아래! 이 개념을 알아야 이해하기 편하다. https://yoomimi.tistory.com/entry/RNN-LSTM-GRU [Deep
yoomimi.tistory.com
우선 Attention과 Transformer에 관한 이해가 필요하다.
1. ViT (Vision Transformer)
Transformer가 자연어 처리 분야에서 SOTA로 쓰이니 CV 쪽에서도 이를 접목해보려 부단히 애썼다. pixel 하나하나 sequence로 생각해 attention을 적용하려고 하거나 한 pixel을 기준으로 이웃 local에 대한 attention을 구하려 하거나 등등. 이 논문, 'An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale'의 Vision Transformer가 그 해답을 찾아냈는데, 이미지를 patch 단위로 나누고 각 patch를 마치 sentence 속 하나의 word로 보고 attention을 적용한 것이다. 결론부터 말하자면 data가 충분할 때 ResNet(당시 SOTA)보다 좋은 Classification 성능을 보였다. (locality 정보가 CNN을 쓸 때보다 시원찮아 data가 충분하지 않으면 generalization에 어려움이 있다.)

모델은 위와 같은 구조를 갖는다. 특히 Transformer Encoder가 기존의 Transformer와 거의 똑같이 생긴 것을 볼 수 있다.
Sentence를 이용할 때와는 달리, image에서는 embedding 방식부터 살펴보아야 하는데, image는 2D이므로 이를 펼쳐야 하기 때문이다. 사진의 왼쪽에서 이미 표현이 됐지만, 3*3의 이미지는 9의 크기를 가진 embedding vector로 표현할 수 있을 것이다. 이때 만약 3D RGB인 상황이라면 3*3*3 이미지가 27의 크기로 flatten되고 27 혹은 다른 원하는 크기로 조작된 사이즈 D를 가진 embedding vector가 될 수 있겠다. 그리고 vector의 각 요소 값에 positional embedding을 더해 encoder에 넣게 된다. 이때 Extra learnable [class] embedding은 BERT의 [class] token처럼 Classification Head(MLP Head)에 입력으로 들어가 Classification에 사용된다. (처음엔 random하게 초기화해서 쓰면 된다.)
동작을 식으로 나타내면 위와 같다. MSA는 Multihead Self-Attention, LN은 Layer Normalization을 나타낸다. ViT의 MLP는 결국 Classification을 하기 위해 있는 것이니, 보통 FC > GELU > FC 구조를 사용한다.
여기서 중요한 개념, Inductive Bias가 있다. ViT는 CNN이 가지는 Inductive Bias를 덜 가졌다. Locality와 Translation Invariance가 이에 해당한다. CNN은 kernel size를 가지고 input image를 보게 된다. 이는 이미지의 인접한 픽셀들이 유의미한 관계를 가진다는 가정, 사람으로 따지면 관념정도로 표현할 수 있는 Inductive Bias를 갖고 있는 셈이다. CNN은 이러한 가정에 기반해 이미지를 local 단위로 뜯어보며 실제로 그 안에서 feature 정보를 얻어낸다.
CNN은 필터를 이미지 전체에 걸쳐 이동시키며 동일한 연산을 수행하는데, 특정 pattern이 어디에 있든 같은 object를 나타내는 것이라는 가정을 하는 셈이다. (정보는 local안에 있으니 이미지를 local(filter)단위로 뜯어는 보되, 각 local에 동일 연산을 먹이고 특정 정보가 다른 local에서 나타난다고 다른 정보라고 인식하지 않는 다는 것이다.)
결국 CNN은 강력한 Inductive Bias를 가지기 때문에 상대적으로 적은 양의 데이터로도 좋은 성능을 낼 수 있지만, ViT는 그렇지 않게 된다. 오히려 여기서 신기한 점은, ViT가 CNN에 비해 적은 data로는 성능이 안 나오는 이유가 CNN이 마치 사람과 같은 '가정'이 부과된 애라 그럴 뿐이라는 것과, ViT도 data만 많이 넣어주면 가정 설정이 부족했던 아이가 많은 data를 통해 알아서 이 부분을 보완해 좋은 성능을 낸다는 것이다.
결과적으로 데이터셋의 크기에 따른 사전 학습 후 전이 학습 성능 비교에서 위와 같이 ResNet을 뛰어넘는 성능을 보였다.
2. ViViT (Video Vision Transformer)
이번에는 Video에 Transformer를 적용한 ViViT다. Video Classification을 위해 Transformer 개념을 사용한 것이다. Transformer를 이용해 video의 공간적, 시간적 token을 추출하고, 이 token을 다시 잘 factorise하는 아이디어다. 또한 이 모델은 3D convolutional network(시간축으로도 conv filter가 움직이는 network)를 포함해 당대 SOTA를 뛰어넘는 성능을 보였다.
Transformer는 long range contextual relationship에 강하기에 Video에 사용하면 좋겠다는 생각은 당연히 할 법한 생각이다. (Video는 시간에 대한 sequential 정보를 담은 4D tensor(프레임, 채널, 높이, 너비), Batch까지 하면 5D tensor다.) ViViT는 ViT 이후 곧바로 나온 연구로, ViViT 이전의 Video Classification은 주로 3D CNN과 이에 따라 늘어난 파라미터를 효율적으로 연산하기 위한 factorization 연구로 이루어져있었다. ViViT는 3D CNN 대신 Transformer를 사용했고, 자신들의 모델에서 시공간 정보를 factorise하는 방법까지 제안한다. (ViViT 이전에 Video Transformer로 TimeSformer나 VTN이 있었다.)
Embedding methods
우선 모델 구조를 파헤쳐보기 앞서 video는 time dimension이 추가되었기에 Tokenization(token embedding과 position embedding)을 2D image와는 다른 방식으로 해줘야 한다. 이에 대한 두 가지 방법론은 아래와 같다.
위 사진은 방법1, Uniform frame sampling이다. input이 RGB image라면 3*3*3이었을 것을, 만일 RGB video with 5 frames라면 3*3*3*5가 되는 것이다. frame을 독립적으로, ViT에서 그랬던 것처럼 flatten해준다. 이러면 결국 전체 비디오를 하나의 커다란 2D image로 생각해 transformer에 넣어주는 것이다.
그 다음은 방법2, Tubelet embedding이다. frame단위로 나누지 않고 tube 단위로 비디오를 나누자는 아이디어인데, 이렇게 하면 tube가 시공간적 정보를 모두 담고 있게 된다. 이러면 차원이 하나 더 늘어나게 되지만(patch 각각이 부피를 가지기 때문에), 시공간적 정보를 모두 담을 수 있게 된다.
Model architecture
이제 다시 모델 구조를 보자.
논문에서 제시한 것은 Factorised encoder / Factorised Self-Attention / Factorised Dot-Product 방식인데, 우선 이것들 전에 Spatio-temporal attention방식, 즉 frame을 그냥 ViT에 넣는 방식을 먼저 생각해볼 수 있다.
그런데 이 방식은 ViT의 Multi-Headed Self Attention(MSA) 때문에 token 개수에 연산량이 quadratic하게 증가하기 때문에 좋지 못하다.
그래서 Spatial 정보와 Temporal 정보를 따로 다루면서도 연산 효율을 위한 Factorization을 추가한 세 가지 방법론을 제안한다.
그림의 Red box, Transformer Encoder가 단순히 ViT의 MSA에 집어넣는 방식이었다.
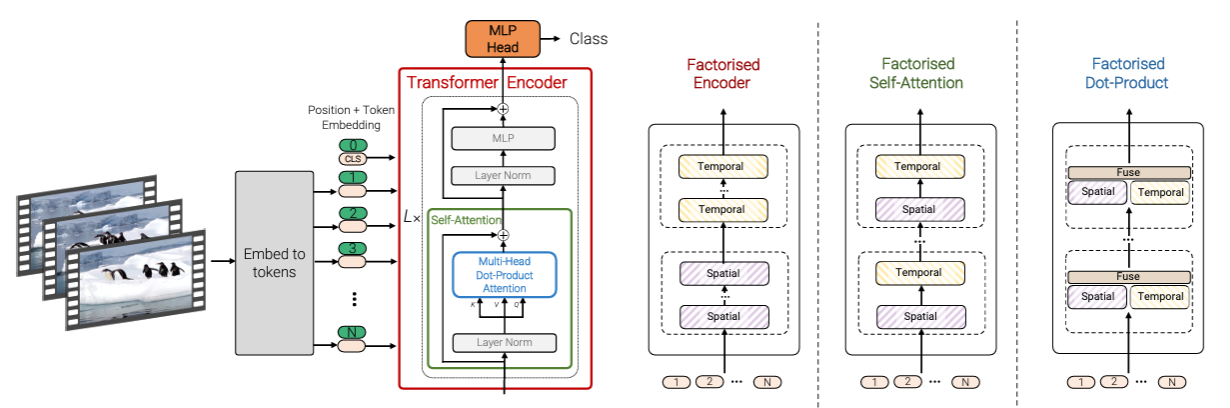
1. Factorised encoder
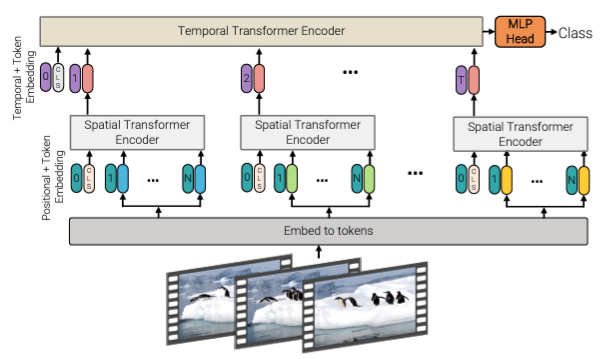
여기서는 Spatial Transformer Encoder과 Temporal Transformer Encoder로 나뉘는 두 개의 Encoder를 사용한다. Spatial Encoder는 하나의 Temporal index(한 frame)에서의 공간 정보를 학습한다. Temporal Encoder에서는 Spatial encoder에서 나온 정보를 다시 tokenization해 시간 정보를 학습한다. 이는 Video classification task에서 흔히 쓰이던 "late fusion"과 유사한 방법으로, 기존 모델보다 parameter는 많아졌으나 결과적인 연산량은 spatial-temporal 분리로 인해 줄어들었다.
2. Factorised Self-Attention
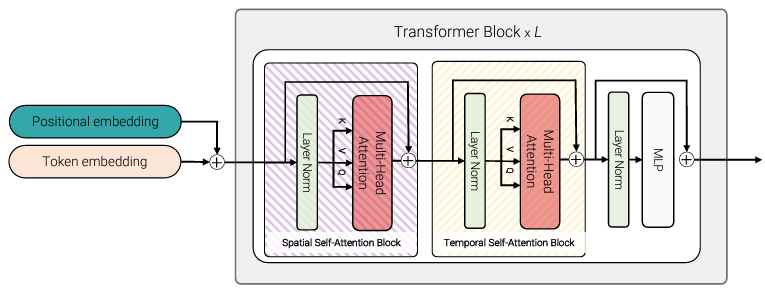
여기서는 크게 Spatial SA Block과 Temporal SA Block 이렇게 두 개의 Self-Attention Block을 사용한다. Spatial/Temporal dimension이 첫 번째 dimension이 되도록 token을 reshape해 Transformer Block에 집어 넣으면, spatial token은 spatial block에서만, temporal token은 temporal block에서만 연산된다. 정확히는 처음에 Spatial에 맞춰 넣고 Spatial SA Block을 거치고 나면 Temporal에 dimension을 맞춰 넣어 연산하는 식이다. (실험결과 Temporal 후 Spatial을 해도 결과가 같다고 한다.) 이렇게 하면 Layer 개수는 그대로지만 Attention block이 늘어나므로 parameter 수가 증가한다. 이 단계에서는 class token을 넣으면 reshape을 하며 input이 ambiguous해져 class token을 넣지 않았다.
3. Factorised Dot-Product
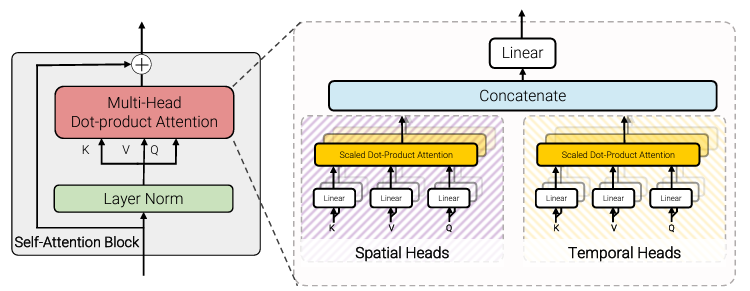
여기서는 Spatial/Temporal 두 개의 Attention Heads를 사용했다. Spatial과 Temporal 각각에 대한 Key, Value를 따로 뽑아 Spatial은 Spatial대로, Temporal은 Temporal대로 Dot-Product를 이용해 attention weight를 뽑아 이를 Concate nate해 attention으로 사용했다.
Weight initialization
그러면 이제 남은 해결 과제는 ViT에서도 그랬듯 많은 data를 써야만 이뤄지는 generalization 문제다. 이를 위해 ViViT는 ViT의 pretrained weight를 사용하고자 했는데, 문제는 역시 image to video였다. 이미지로 pretrained된 weight를 활용하기 위해 그들이 제안한 방법론은 다음과 같다.
Positional embedding : 단순히 frame마다 ViT에서 사용된 같은 embedding을 반복시킨다.
Embedding weights : Uniform embedding이 아닌 Tubelet embedding을 사용할 경우, 아래의 initialization 방법들을 사용할 수 있다.
- Filter inflation (with averaging) : 각 frame별 embedding의 평균을 계산하고 이를 inflate한다.
- Central frame initialization : 가장 가운데 position(T/2)의 frame을 제외하고 전부 zero initialization한다. 이렇게 하면 tublet embedding이 마치 uniform embedding처럼 보이게 되니(matrix 하나당 값이 하나니까 차원 하나가 줄어든 셈) tublet을 하나의 frame처럼 쓸 수 있게 된다.
MSA module : 이 방식은 video는 image에서 시간축만을 추가한 것이므로 temporal을 zero initialization에서 출발하겠다는 아이디어다. Factorised Self-Attention의 경우 Attention module이 2개이므로 spatial은 pretrained된 것을 사용하고 temporal은 zero initialization을 한다.
Result
방법론 여러개가 제시되었으니 각 조합과 모델마다 Result도 나왔다.
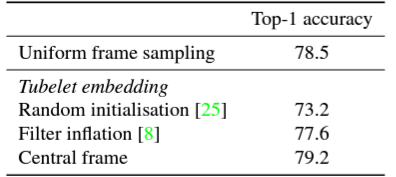
Embedding과 weight initialization에서는 결과적으로 Tubelet embedding 후 Central frame initialisation으로 weight initialization 조합이 가장 높은 성능을 보였다. Tubelet이 항상 좋은 것만은 아니기에 Uniform도 소개를 했겠다. Filter inflation을 쓰는 것보다는 Uniform embedding을 쓰는 것이 성능이 좋았다.
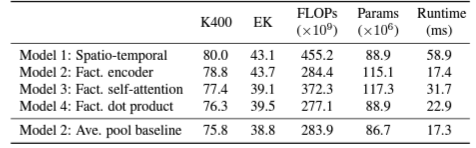
모델은 Factorised encoder이 Fact. 중 가장 성능이 좋고 Runtime도 짧았으며, Ave. pool baseline을 이용하면 reguralization도 잘 먹혀, 결과적으로 작은 dataset에서도 Transformer를 효과적으로 사용할 수 있는 가능성이 보였다. Spatio-temporal attention 방식도 data가 많을 때는 성능이 괜찮았다. 하지만 Input frame이 많아지면 성능이 saturate되어(frame 개수에 따라 연산량 quadratic 증가) 결국 video data가 적거나 길이가 긴 영상을 보여주는 상황에서는 Factorised encoder를 쓰는 것이 효과적이다.
추가로 tubelet size를 작게 하거나 spatial resolution을 키울수록 성능이 개선되었다.
[참고자료]
* (ViT Paper) https://arxiv.org/abs/2010.11929
* (ViViT Paper) https://arxiv.org/abs/2103.15691
'Study > Computer Vision' 카테고리의 다른 글
| [CV] Statistical object recognition, PCA/LDA, SVD (1) | 2024.06.09 |
|---|
